![]()
Architecting AWS-Powered Microservices in Python with Serverless Framework: What You Need to Know
We have been talking a lot about the new serverless cloud over the last few months. The news is all good. There have been tremendous improvements announced since AWS Lambda’s launch in 2014. Competing cloud vendors are working hard to catch up with AWS when it comes to serverless infrastructure-as-a-service.
Developing in a serverless fashion will definitely improve the life of developers and DevOps professionals — although we are still in the early days of this revolution.
Smart developers quickly realized the need for automation and structure, especially when orchestrating a nontrivial system of APIs and microservices.
In this post, we’re going to cover the following topics:
- The history of Serverless Framework.
- The basics of architecting applications in Serverless Framework.
- The Serverless Framework command-line interface (CLI).
- How to develop Serverless Framework applications in Python.
The Serverless Framework: A Brief History
![]()
With the goal of making the serverless transition smoother for everyone, the AWS community started working on a complete solution to develop AWS-powered microservices or backends for web, mobile, and IoT applications. The migration required facilitation because of the building-block nature of AWS Lambda and its complex symbiosis with Amazon API Gateway.
That’s how the Serverless Framework was born (formerly JAWS). Thanks to the hard work of @austencollins, JAWS made it to the HN homepage last Summer and was successfully presented at re:Invent 2015 in Las Vegas, Nevada thereafter.
To date, the project counts more than 60 contributors on GitHub and boasts an active ecosystem of plugins and tutorials. Take a look at an awesome curated list of resources related to the Serverless project.
ServerlessConf and the Serverless Community
The future will be Serverless. [@ServerlessConf]
The Serverless community is constantly growing, and not only within the AWS ecosystem. It is robustly supported by active meetups in San Francisco, New York, Melbourne, and Sydney.
If you feel like witnessing history in NYC, keep an eye on the (sold out) ServerlessConf this week. I will personally attend the event, and I’ll be glad to meet you there.
It will be fun to attend, but don’t panic if you didn’t secure a ticket. All the videos will be available online after the event.

Serverless Framework: The Basics
The Serverless Framework forces structure into serverless code by providing a minimal and clear organization for your lambda functions. The advantage of this structure means you will benefit from all the AWS best practices that were painstakingly built into in the framework. This structure effectively frees developers from low-level details about versions, aliases, stages, variables, roles, etc.
Rising above these details leaves room for greater productivity (and maybe a longer lunch).
As a software engineer, this freedom from drudgery allows you to focus on the business logic — which is the main goal of AWS Lambda itself.
On the operations side, the framework will also take care of the deployment process, which can easily become the most annoying part of using AWS Lambda – especially if your use case is complex.
Typically, you would need to bind together Lambda functions and API Gateway endpoints, configure the request/response integrations, deal with multiple stages and aliases (i.e. dev, prod, etc.), build, and upload your deployment package.
Once you successfully complete these steps, you’ll likely be required to do it again in more than one AWS region.
Installation and Code Organization
The Serverless Framework is built in JavaScript and requires Node V4. You can install it via npm:
npm install serverless -g
Once the package is installed globally, you can create or download a new project and start working on your Lambda functions in JavaScript (Node.js 0.10 or 4.3) or Python 2.7.
Most of the time, your Lambda functions will require some external dependencies. Keep in mind that you will need to upload these libraries together with your own code.
Finally, the compiled code must be compatible with the operating system used by AWS Lambda under the hood (e.g. CentOS).
The Serverless Framework suggests developers organize their code as follows:
- Group your functions into subfolders
(i.e. “/functions/myfunction1/“, “/functions/myfunction2/“, etc.) - Define a module to share common code among your functions
(i.e. “/functions/lib/“), this way you will separate the Lambda boilerplate from your core logic - Define your dependencies as a package.json or requirements.txt file, eventually for each function, so that you install them via npm or pip: the framework will take care of zipping and uploading your node modules or Python Virtualenv.
Please note that the framework is still in Beta release (currently v0.5.5) and future versions might contain breaking changes due to the quickly evolving serverless landscape. That said, I am confident that most of the above mentioned best practices are fairly stable, as are the following ones.
Serverless Framework CLI and Concepts Overview
The framework exposes an interactive CLI that lets you manage and automate every phase of your workflow. You’ll need to become comfortable with the following critical concepts:
- Projects: you can configure independent serverless projects, either by starting from scratch or from ready-to-use, installable and shareable projects (available as npm packages).
- Plugins: the framework comes with a rich set of plugins that add useful functionalities to the core, such as CORS support, code optimization, and linting, Cloudwatch + SNS logging, TDD, and others. Feel free to create and publish your own plugins to better structure and share your code. There is also an official plugins registry.
- Stages: each stage represents an isolated environment, such as dev or prod. You can use them to separate and isolate your AWS resources. As a best practice, the framework lets you start with a default dev stage.
- Regions: these are an exact mapping of the official AWS regions. You may want to deploy each stage into a different region to achieve total separation, or even distribute your resource across multiple regions to optimize your system performance.
- AWS Profiles: each profile corresponds to a valid combination of your AWS account access keys. You may want to use a different profile for each stage and eventually use totally different AWS accounts.
- Functions: functions are the real core of your project, and the Serverless framework lets you organize them as you like, even if some sort of structure is highly recommended (really). Each function will ultimately correspond to a folder in your file system, with its own code (only JavaScript or Python, for now), its configuration, and a test event.
- Endpoints: each function can potentially be bound to multiple endpoints, which correspond to API Gateway resources and methods (i.e. HTTP endpoints). You’ll need to declare them in each function configuration.
- Events: if you need to invoke your function upon particular events – or in a recurring basis – you can declare a set of events in its configuration file (e.g. dynamodbstream, kinesisstream, s3, sns or schedule).
- Resources: for each stage and region, you can define a set of CloudFormation resources, such as IAM roles, policies, etc. Interestingly, you can easily show the diff between your local configuration and the deployed resources.
- Templates & Variables: these are a useful tool to reduce the size and redundancy of your configuration files. Variables can hold only numbers and strings, while templates allow you to define complex structures, in a hierarchical fashion.
- Dashboard: the framework provides an interactive deployment dashboard, to visualize and select which resources to be deployed concurrently. You can also be shown a graphical summary of the current status of your project (see screenshot below).

A Real-World Serverless Example in Python
The Serverless Framework comes with a very useful boilerplate project for JavaScript functions. It will give you a great overview of how to organize your projects and provide a stable base to bootstrap a new one.
I personally took the time to create a new starter project for Python functions.
You can quickly download and install it by executing the following command:
serverless project install serverless-starter-python
This project, in particular, doesn’t come with any dependencies, but normally you’d need to install them via npm:
cd serverless-starter-python npm install
Then, you will need to install your Python dependencies in a specific folder, as follows:
cd restApi pip install -t vendored/ -r requirements.txt
Note: the “restApi” folder contains all our functions in this project. Eventually, you can have more than one root-level folders, and even sub-folders (see “restApi/multi/show” and “restApi/multi/create“).
But let’s focus on “restApi/continent“: this Lambda function takes a country name as input (e.g. “Germany“) and will return the corresponding continent (e.g. “Europe“). In order to demonstrate how to use Python dependencies, I implemented the function by using the countrycode module (see requirements.txt).
As a best practice, I organized the Lambda function code as follows:
- “restApi/continent/handler.py” only contains the basic handler logic, plus some sys.path magic to include the common library.
- “restApi/lib/continent.py” defines a continent_by_country_name function, which implements the actual business logic.
- “restApi/lib/__init__.py” takes care of exposing the library utilities and including our Python dependencies in the sys.path (the “vendored” folder where we installed our requirements).
Here is the main function logic:
from countrycode import countrycode
def _error(msg):
""" Utility to handle custom errors (see response mapping) """
raise Exception("[BadRequest] %s" % msg)
def continent_by_country_name(event):
""" Get continent name (e.g. "Europe"), given a country name (e.g. "Italy") """
country_name = event.get('country')
if not country_name:
return _error("Invalid event (required country)")
continent = countrycode(codes=[country_name], origin="country_name", target='continent')
if not continent:
return _error("Invalid country: %s" % country_name)
return {
"continent": next(iter(continent)),
}
In order to demonstrate how to handle errors, I have wrapped the required logic in a _error function: it will simply raise a Python Exception with a well-defined structure. Indeed, here is how I defined the corresponding endpoint responses:
{
"name": "continent",
"runtime": "python2.7",
"handler": "continent/handler.handler",
...
"endpoints": [
{
"path": "continent",
"method": "GET",
"requestTemplates": "$${apiRequestTemplate}",
"responses": {
"400": {
"selectionPattern": "^\\[BadRequest\\].*",
"responseModels": "$${apiResponseModelsError}",
"responseTemplates": "$${apiResponseTemplateError}",
"statusCode": "400"
},
...
}
}
]
}
As you can see in the “selectionPattern” definition, API Gateway will match any “[BadRequest]” prefix whenever you raise a Python Exception and bind it to a 400 – Bad Request HTTP response. Here you can see Templates in action: you can define and re-use them everywhere with the $${NAME} syntax.
Furthermore, I customized how the HTTP response is sent back in case of 400 errors, in our “restApi/continent/s-templates.json”:
{
"apiRequestTemplate": {
"application/json": {
"country": "$input.params('country')"
}
},
"apiResponseModelsError": {
"application/json": "Error"
},
"apiResponseTemplateError": {
"application/json": {
"message": "$input.path('$.errorMessage')"
}
}
}
Here I defined three templates:
- apiRequestTemplate is used to map the querystring “country” parameter into an explicit event parameter;
- apiResponseModelsError associates API Gateway’s default Error model to our 400 response, which contains only a “message” parameter;
- apiResponseTemplateError defines how to build our 400 HTTP Response body and is particularly useful if you want to hide the default stack trace and map “errorMessage” into the model’s “message” parameter.
Let’s test our function locally.
I have defined a local test event in “restApi/continent/event.json“, which contains a simple JSON structure such as {“country”: “Germany”}. You can easily run your function with the following command:
serverless function run continent
If everything went right, the framework will print out something like {“continent”:”Europe”}.
Once you are happy with your functions, you can launch the (beautiful) deployment dashboard:
serverless dash deploy
This dashboard is designed to be interactive. Here you can choose which resources you want to deploy, with a very intuitive interface. As I mentioned earlier, the framework will take care of all the details. It will create new Lambda versions, associate them with the right alias, re-deploy API Gateway stages, update every template mapping, etc.
Here is what the interactive dashboard looks like:
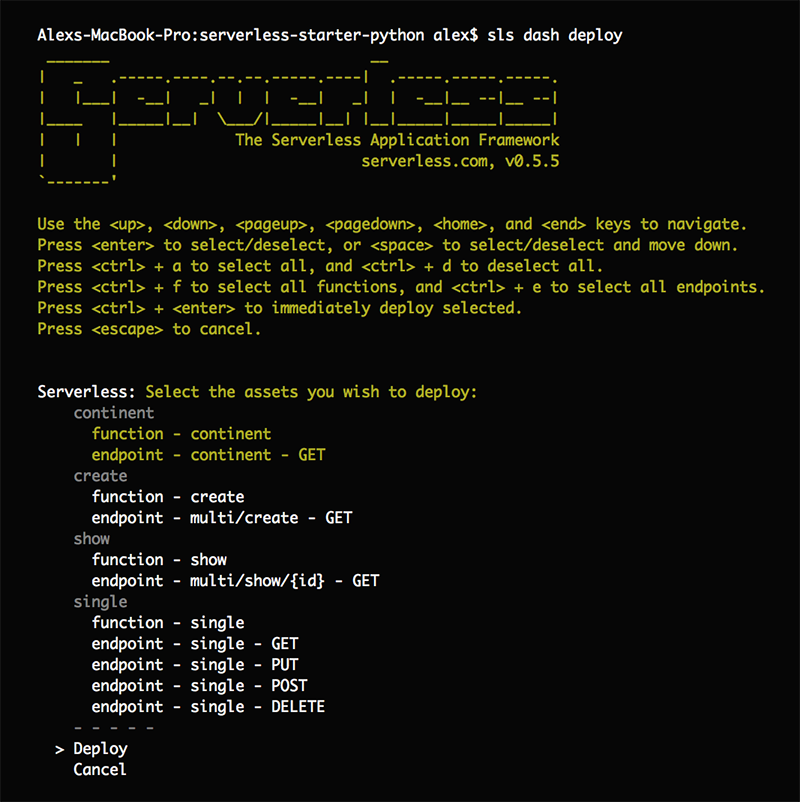
Once you confirm the operation, everything will be checked and deployed smoothly. You will also be given the HTTP endpoints for each updated Endpoint.
Of course, you can also decide to remove your functions and endpoints with a single command:
serverless function remove continent
Keep in mind that the framework will only delete the AWS Lambda aliases and the API Gateway resources associated to the corresponding stage. It means that all your functions versions will be still available on AWS, should you need them later on. This is possible because the framework never uses your Lambda functions’ $LATEST version, which is highly discouraged in general unless you are just prototyping.
More Serverless Resources
I personally believe the Serverless Framework – even if still in Beta – is a complete and robust solution for organizing complex projects. I expect these frameworks will continue improving and continue impressing users with new and more powerful features.
I would like to mention a few more serverless frameworks worth investigating:
- Zappa: facilitates the deployment of all Python WSGI applications on AWS Lambda + API Gateway.
- Kappa: a command line tool that (hopefully) makes it easier to deploy, update, and test functions for AWS Lambda.
- Apex: lets you build, deploy, and manage AWS Lambda functions with ease (with Golang support!).
- Lambda-complex: a Node.js framework for applications that run entirely within Lambda, SQS, and other high abstraction layers AWS services.
- λ Gordon: an automation tool based on self-contained CloudFormation templates (Python, Javascript, Java, Golang and Scala support).
Do You Always Need a Full-Fledged Framework?
Sometimes, you want to keep complexity and friction as low as possible, especially for small projects or experiments. In these cases, you may prefer simpler solutions that better integrate with your existing code and solve only a single problem. Here is a small collection of such projects:
- λambdify: a tool that turns any python callable into an AWS Lambda function.
- Python-lambda: a toolset for developing and deploying serverless Python code in AWS Lambda.
- Cloudia.js: it helps you easily deploy Node.js microservices to Amazon Web Services.
Here’s How You Can Easily Learn the Fundamentals of Serverless Design
There are plenty of resources for learning serverless. Here are some of the best:
- Official AWS Documentation.
- ServerlessCode.com, by Ryan Scott Brown.
- AWS Lambda in Action, by Danilo Poccia.
- Cloud Academy’s blogs, courses, and Labs.
- Serverless Architectures on AWS, by Peter Sbarski.
The Serverless Cloud
It turns out serverless computing is also popular outside of the AWS ecosystem. Every cloud vendor is building its own serverless solution.
Why? Apparently, because developers really like this new level of abstraction. Roughly speaking, not dealing with operations and server maintenance simply sounds better, even without considering the powerful event-oriented approach offered by the serverless architecture.
Even though serverless computing doesn’t completely remove operations from your workflow, I personally believe it makes developers more comfortable, and drastically increases the ownership of their code.
Here are some of the main AWS Lambda alternatives, even if most of them are still alpha versions or not as complete as they should be:
- Google Cloud Functions: here is my review of Google’s serverless solution (still in limited preview); it currently supports only JavaScript.
- Microsoft Azure Functions: Azure’s solution – still in preview – looks very promising, but I haven’t had a chance to try it yet. It supports a wide variety of languages, including JavaScript, C#, Python, PHP, Bash, Batch, and PowerShell.
- IBM Bluemix OpenWhisk: also IBM’s solution is still in alpha and I might give it a try soon. It currently supports JavaScript and Swift.
- Iron.io: it is a serverless platform built on top of Docker and Golang. This one is language agnostic and currently supports Golang, Python, Ruby, PHP, and .NET.
I am still looking forward to a future where a great codebase like the Serverless Framework is vendor neutral and allows developers to work on the Cloud platform of their choice.
Let us know what you like or dislike about serverless computing, especially if you are using the Serverless Framework.